자연어(Natural Language)
사람이 일상 생황에서 사용하는 언어를 자연어라고 합니다.자연어 처리(NLP; Natural Language Processing)

NLP는 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일을 말합니다. 언어학 지식을 인공지능을 이용해서 컴퓨터 과학으로 구현해 어떻게 효율적으로 사용하느냐를 연구하는 분야입니다.
자연어 처리 특징(어려움)
- 복잡성(Complexity)
- 애매함(Ambiguity)
- 의존성(Dependency)
머신러닝 VS 딥러닝

- 머신러닝
- 언어학이 많은 비중을 차지하였습니다. 도메인 지식을 상당히 요하기 때문에, 진입 장벽이 높고 기대효과가 분명합니다.
- 딥러닝
- 도메인 지식의 상당 부분을 Data-Driven으로 해결하여 의외의 Insight를 얻을 수 있습니다.
애플리케이션 소개
- 문장 번역(Machine Translation)
- 감정 분석(Sentiment Analysis)
- 챗봇(Chatbots)
- 문맥 광고(Contextual Advertising)
- 자동 음성 인식(ASR; Automated Speech Recognition)
- 광학 문자 인식(OCR; Optical Character Recognition)
순차 데이터(Sequential Data)
순서가 의미가 있으며, 순서가 달라질 경우 의미가 손상되는 데이터를 순차 데이터라고 합니다. 시간적 의미가 있는 경우 Temporal Sequence라고 하며, 일정한 시간차라면 Time Series라고 합니다. Temporal Sequence는 시간과 Value가 쌍으로 이루어지고, Time Series는 x축을 시간으로 보지 않고 step으로 봅니다.

순환 신경망 종류
순차 데이터셋의 구조 및 네트워크

다중 입력, 단일 출력
- 마지막 입력에는 EOS(Special Token)을 넣어서 문장 종료를 알림
 |
| 다중 입력, 단일 출력 |
단일 입력, 다중 출력
- 입력이 한번 들어온 후 여러 개의 출력을 냄
- 나머지 입력 값은 지정된 값을 입력
- yn의 모든 Loss를 구해서 BP를 수행해서 훈련함
 |
| 단일 입력, 다중 출력 |
다중 입력, 다중 출력
- 입력과 출력이 매 Time-step 마다 이루어지는 경우
- 입출력 길이가 같은 경우
- 동영상 프레임별 분류를 예로 들수 있음
- 농구하는 사진 => 농구한다.
- 축구하는 사진 => 축구한다.
 |
| 다중 입력, 다중 출력 |
- 모든 입력을 받은 후 출력을 내는 경우
- 문장 번역, 챗봇 등을 예로 들수 있음
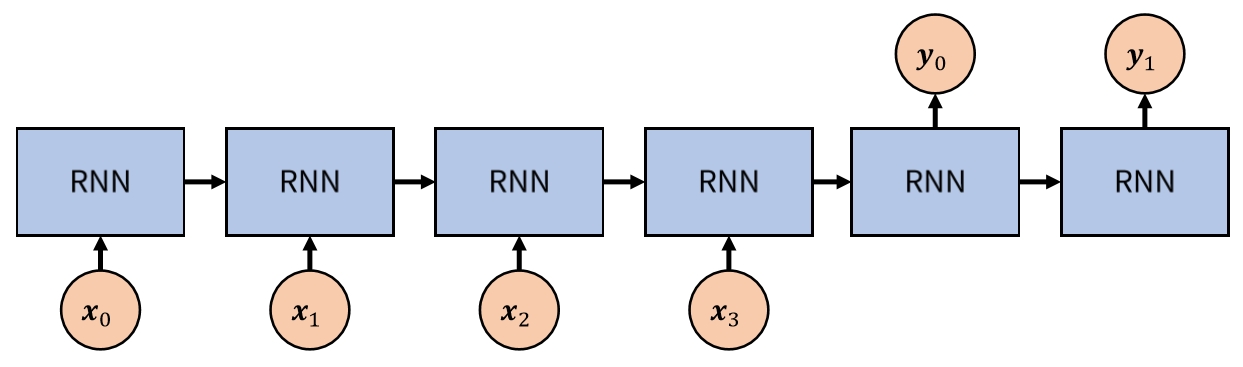

얕은 신경망(Shallow Neural Network)
얕은 신경망은 대표적인 무기억 시스템(Memoryless System)입니다. 무기억 시스템이므로 n번째 타입 스텝에 대한 결과가 이전 입력에 영향을 받지 않습니다. 즉 n번째 입력은 n번째 출력에만 영향을 줍니다.
기억 시스템(Memory System)
입력을 받을 때 마다 그 내용을 기억 시스템에 저장합니다. 이전 입력 데이터는 최종 출력을 위해 사용됩니다.
순환 신경망(Vanilla Recurrent Network)
Vanilla RNN은 기억시스템으로, 출력은 이전의 모든 입력에 영향을 받습니다.
n번째 hidden state 연산식을 보면, 현재 입력과 이전 hidden state의 정보를 함께 이용하여 출력을 만듭니다.
감사합니다.
- Fast Campus
댓글
댓글 쓰기