경사 하강법은 다음을 참고 바랍니다.
https://www.blogger.com/blogger.g?blogID=3314074563645120473#editor/target=post;postID=6213959223488853886;onPublishedMenu=allposts;onClosedMenu=allposts;postNum=1;src=postname
모델 학습 아키텍쳐

- 학습 목표는 손실을 최소화하는 매개 변수를 찾음
- 학습 데이터, Model, 손실 함수는 정해져 있음
- Model은 Trainable Parameters에 의해 변경됨
방법
- 손실 함수를 입력 값으로 미분하여 Gradient Descent 방법으로 매개변수를 변경함.
매개 변수가 4개일 때 예제입니다. 각 매개 변수에 대해 편미분을 수행하고 다음 가중치를 구합니다.

역전파 학습법 (Back-Propagation(BP))

- 학습 데이터로 정방향 연산을 하여 Loss를 구함
- 연쇄 법칙을 이용해 역전파 학습법 수행함
- Loss를 각 파라미터로 미분함
- 마지막 계층부터 이전 계층으로 연쇄적으로 계산
- 역전파 연산 시 정방향 연산에서 저장한 결과응 사용하여 연산 수를 줄임

- Loss를 각 파라미터로 미분함
- 마지막 계층부터 이전 계층으로 연쇄적으로 계산
- 역전파 연산 시 정방향 연산에서 저장한 결과응 사용하여 연산 수를 줄임
연쇄 법칙 (Chain Rule)
심층 신경망은 여러 층으로 쌓여 있으므로 학습 데이터 x로 비용 함수 결과를 미분하기 위해서는 연쇄 법칙을 이용해야 합니다.
동적계획법(Dynamic Programming)
feed forward 계산해서 back propagation에 미분에 필요한 값을 저장하고, Loss 구하고 연쇄법칙으로 미분값 계산한 결과값을 저장하고 동적계획법으로 계산합니다.
전결합 계층 미분
활성 함수를 제거하고 모든 매개 변수로 미분을 수행한 결과입니다.

- hidden layer의 출력으로 미분하면 계수 weight만 남음
- weight로 미분하면 hidden layer 출력만 남음
- 편향은 상수이므로 1이 됨

- 활성 함수 결과를 전결함 계층으로 미분한 결과를 곱함.
연쇄 법칙을 이용한 심층 신경망 미분
연쇄 법칙을 이용하여 연속된 함수의 미분을 각각의 미분의 곱으로 표현할 수 있습니다. 중간 과정을 저장해서 여러 Chain에서 사용할 수 있습니다(Dynamic Programming).
심층 신경망에서 Loss를 미분하는 방법을 그림으로 표현합니다.
- 출력 계층 미분: 손실 함수 결과를 미분 필요함
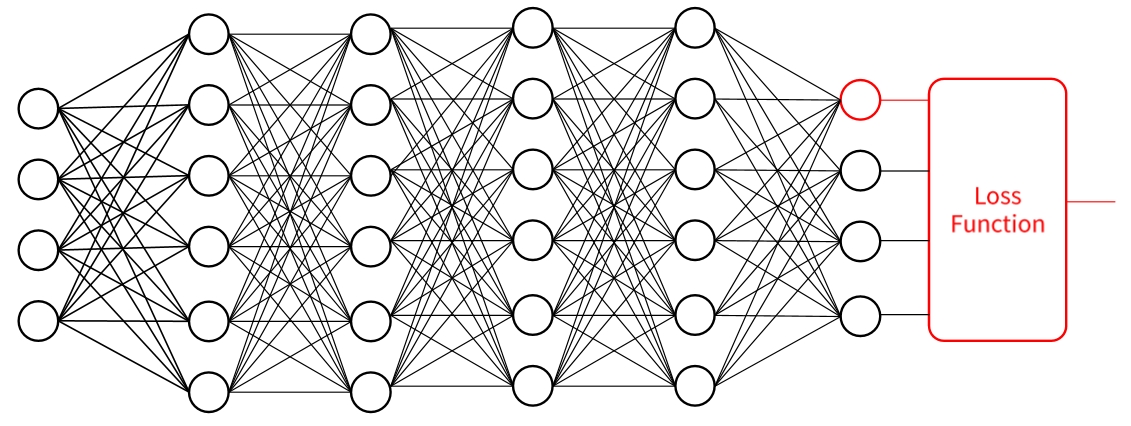
- 마지막 은닉 계층 미분: 손실 함수, 출력 계층의 미분 필요, 동적 계획법을 이용해 중복 연산 제거함.

- 은닉 계층 미분: 손실 함수, 출력 계층, 사이의 모든 은닉 계층의 미분 필요함


변할수 있는 값은 매트릭스 W와 벡터 편향 b입니다. 로스 L에 대한 미분 방법은 다음과 같습니다.

감사합니다.
- Fast Campus
댓글
댓글 쓰기